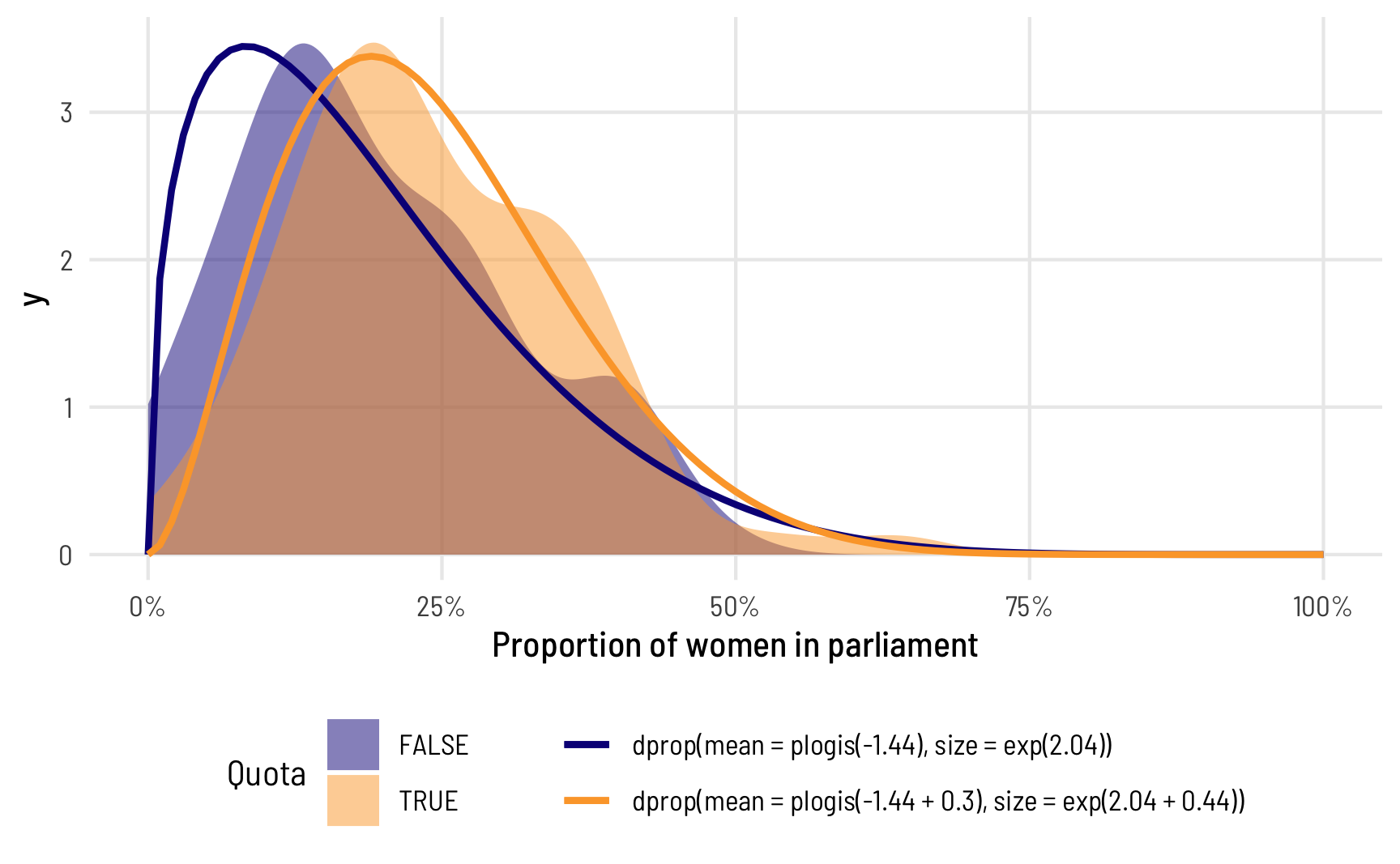
RTidyverseRegressionStatisticsBayesPolitical Science
Published
Author Andrew Heiss
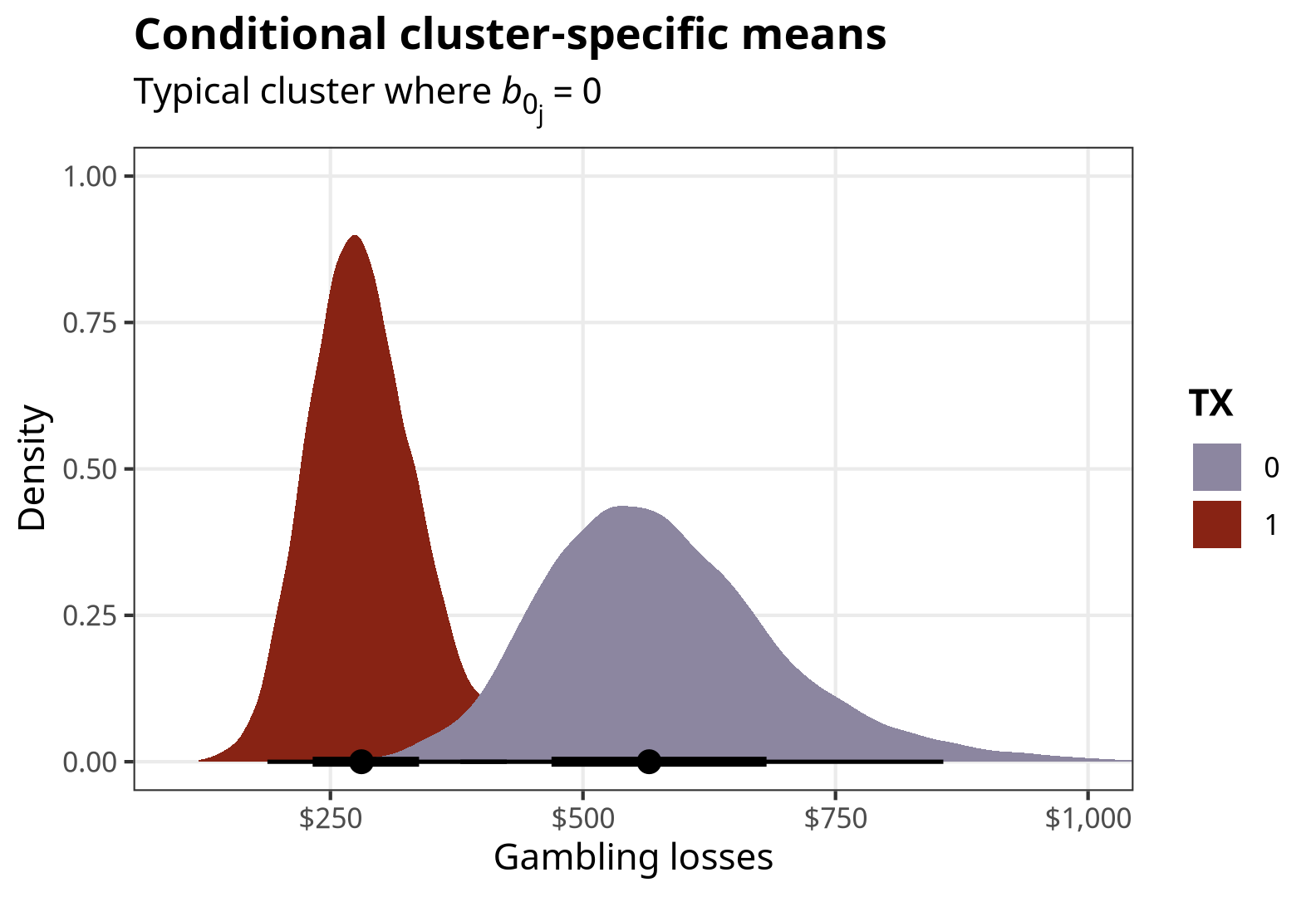
As a field, statistics is really bad at naming things. Take, for instance, the term “fixed effects.” In econometrics and other social science-flavored statistics, this typically refers to categorical terms in a regression model.