Published
Author Egon Willighagen
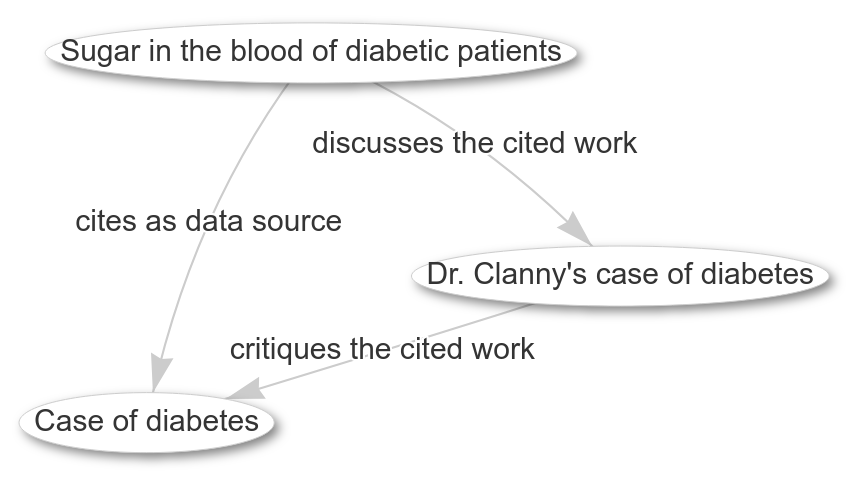
Diabetes was already discussed in literature back in 1838-1839 (doi:10.1016/S0140-6736(02)96038-1, doi:10.1016/S0140-6736(02)96066-6, and doi:10.1016/S0140-6736(02)83966-6). These three papers show a short discussion.