APICrossrefInfrastructureComputer and Information Sciences
Published
Since we first launched our REST API around 2013 as a Labs project, it has evolved well beyond a prototype into arguably Crossref’s most visible and valuable service.
Since we first launched our REST API around 2013 as a Labs project, it has evolved well beyond a prototype into arguably Crossref’s most visible and valuable service.
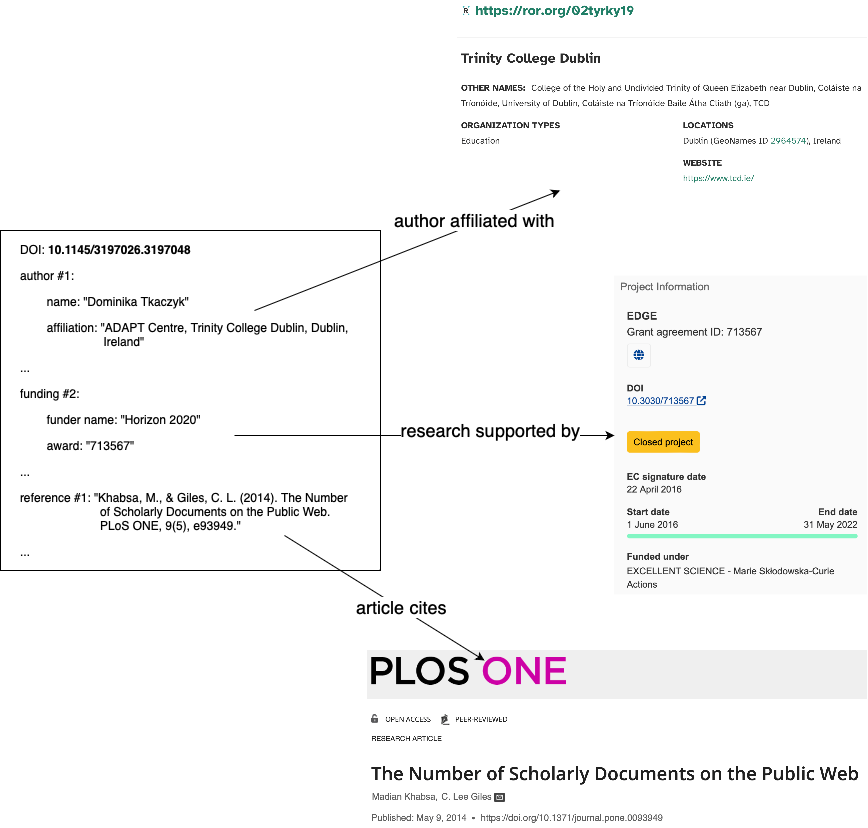
https://doi.org/10.13003/aewi1cai At Crossref and ROR, we develop and run processes that match metadata at scale, creating relationships between millions of entities in the scholarly record. Over the last few years, we’ve spent a lot of time diving into details about metadata matching strategies, evaluation, and integration.
This year’s public data file is now available, featuring over 156 million metadata records deposited with Crossref through the end of April 2024 from over 19,000 members. A full breakdown of Crossref metadata statistics is available here.
Earlier this year, we reported on the roundtable discussion event that we had organised in Frankfurt on the heels of the Frankfurt Book Fair 2023.
Crossref is undertaking a large program, dubbed 'RCFS' (Resourcing Crossref for Future Sustainability) that will initially tackle five specific issues with our fees.
The Crossref Nominating Committee is inviting expressions of interest to join the Board of Directors of Crossref for the term starting in January 2025. The committee will gather responses from those interested and create the slate of candidates that our membership will vote on in an election in September.
This past year has been a captivating journey of immersion within the Crossref community, a mix of online interactions and meaningful in-person experiences.
One of the challenges that we face in Labs and Research at Crossref is that, as we prototype various tools, we need the community to be able to test them.

When each line of code is written it is surrounded by a sea of context: who in the community this is for, what problem we’re trying to solve, what technical assumptions we’re making, what we already tried but didn’t work, how much coffee we’ve had today.

It turns out that one of the things that is really difficult at Crossref is checking whether a set of Crossref credentials has permission to act on a specific DOI prefix.
Subject classifications have been available via the REST API for many years but have not been complete or reliable from the start and will soon be deprecated.