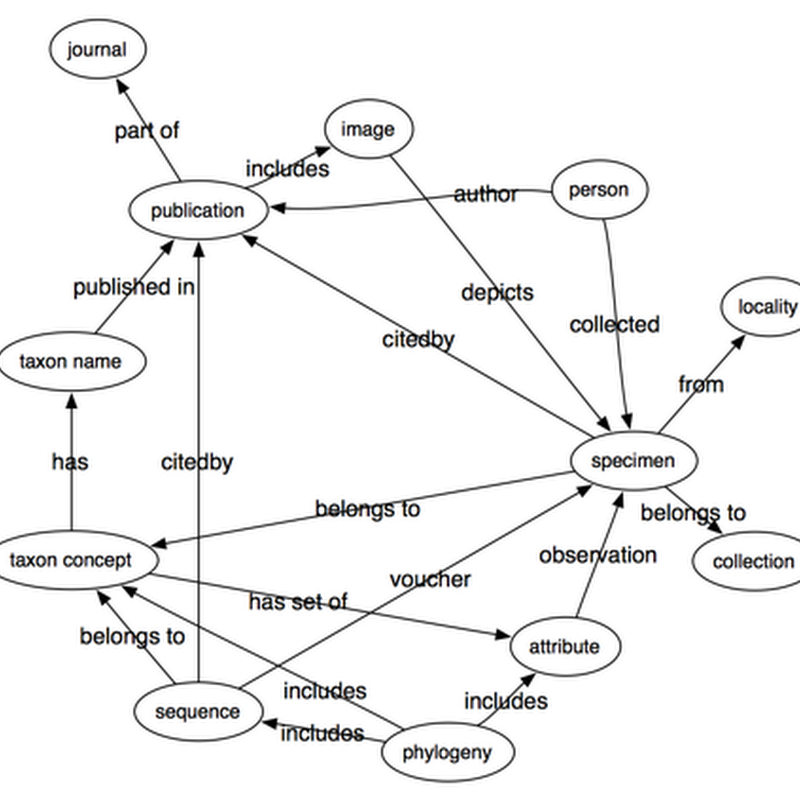
Open DataTaxonomic DatabasesComputer and Information Sciences
Published
Author Roderic Page
Few things have annoyed be as much as the following post on TAXACOM: I'm trying to work out why this seemingly innocuous post made me so mad. I think this is because I think this fundamentally framing the question the wrong way. Surely the goal is to have a list of names that is global in scope, well documented, and freely usable by all without restriction? Surely we want open and free access to fundamental biodiversity data?