Other Social Sciences
Published
Author Aaron Tay

A decade ago in 2012, I observed how the dominance of Google had slowly affected how Academic databases and OPACs/ catalogues (now discovery services) work.
A decade ago in 2012, I observed how the dominance of Google had slowly affected how Academic databases and OPACs/ catalogues (now discovery services) work.

On September 2023, OpenAI announced that ChatGPT Plus would be enhanced in three ways 1. It would allow you to speak directly with GPT and it would also be able to reply in voice 2. It would be able to create images using DALL-E 3, OpenAI's image generation model 3. It would be able to accept image inputs Since I finally gained access to these features, I will briefly review them with my thoughts on how impactful they might be for library

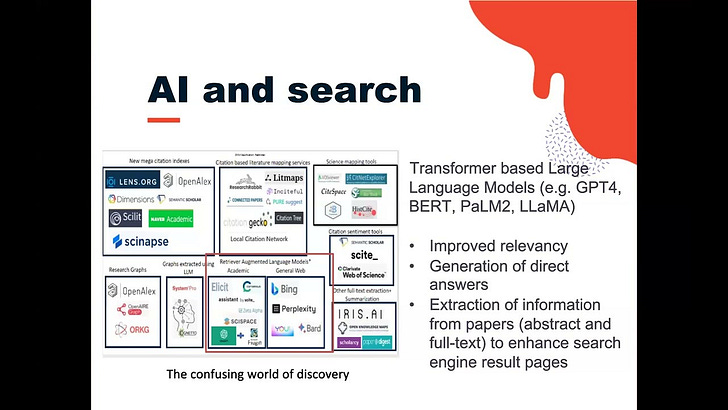
List of academic search engines that use Large Language models for generative answers (for the latest version - see this page) This is a non-comprehensive list of academic search engines that use generative AI (almost always Large language models) to generate direct answers on top of list of relevant results, typically using Retrieval Augmented Generation (RAG) Techniques. We expect a lot more!

One of the earliest themes of this blog was to track tools that not only helped with discovery but also with delivery, helping users to gain access to full-text via institution subscriptions (and of course via Open Access) even if they did not start off the library homepage.

I've been a subscriber of OpenAI's ChatGPT plus for a while though I have been struggling to justify it to myself for a while until recently.
I was asked to give a talk at CILIP Conference 2023 for the Data & AI panel. I was given 10 minutes to send a recording which I eventually delivered. But here's an extended 40-minute recording before I cut it down. As I was just practicing, the delivery might not be the best, and in fact the final 10-minute version might be better!

As expected more academic search engines are starting to adopt the near-human Natural language understanding and natural language generation capabilities of Large Language Models. This seems to be done in two main ways. Firstly, it is used to help generate direct answers to questions.

In recent years, Elsevier has provided relatively good access to their content via APIs, whether it be via the Scopus API for metadata including bibliometrics or even full-text via Sciencedirect API as long as you are an institutional customer, typically at no additional fee. My suspicion is this feature isn't that well known even among librarians.

Edit: Since writing this I have watched the Video - State of GPT | BRK216HFS by Andrej Karpathy(Open AI). In 42 minutes, it not only covers the basic high-level details on how auto-regressive decoder only models work (e.g.; GPT models) but has the clearest explanation on why prompt engineering works.
ChatGPT by OpenAI is the most famous and most used auto regressive decoder Transformer based Large Language Model. However, it is not the only large language model, besides open ones like BLOOM, Google has developed their own versions include LaMDA, and Pathways Language Model (PaLM) both in 2022, but had never released them any of them, until now.

The story so far. ChatGPT, or other large language models, is not ideal for information retrieval alone because it often hallucinates or fabricates information, including references.