Published
Author Jeroen Ooms
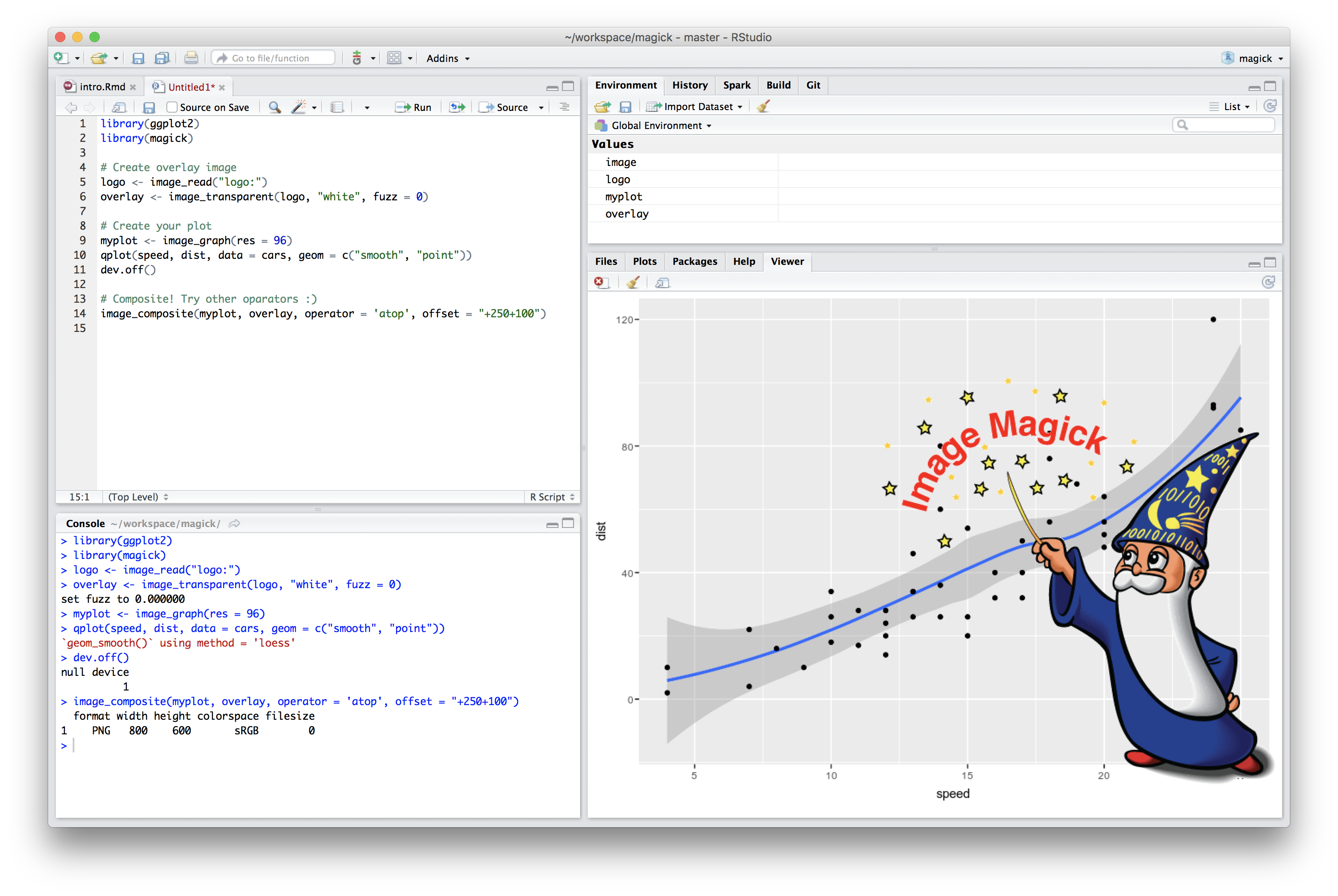
Last week, version 1.0 of the magick package appeared on CRAN: an ambitious effort to modernize and simplify high quality image processing in R. This R package builds upon the Magick++ STL which exposes a powerful C++ API to the famous ImageMagick library. The best place to start learning about magick is the vignette which gives a brief overview of the overwhelming amount of functionality in this package.