
Published
Author Henry Rzepa

Linear free energy relationships (LFER) are associated with the dawn of physical organic chemistry in the late 1930s and its objectives in understanding chemical reactivity as measured by reaction rates and equilibria.
Linear free energy relationships (LFER) are associated with the dawn of physical organic chemistry in the late 1930s and its objectives in understanding chemical reactivity as measured by reaction rates and equilibria.
The traditional structure of the research article has been honed and perfected for over 350 years by its custodians, the publishers of scientific journals. Nowadays, for some journals at least, it might be viewed as much as a profit centre as the perfected mechanism for scientific communication. Here I take a look at the components of such articles to try to envisage its future, with the focus on molecules and chemistry.
For perhaps ten years now, the future of scientific publishing has been hotly debated. The traditional models are often thought to be badly broken, although convergence to a consensus of what a better model should be is not apparently close. But to my mind, much of this debate seems to miss one important point, how to publish data.
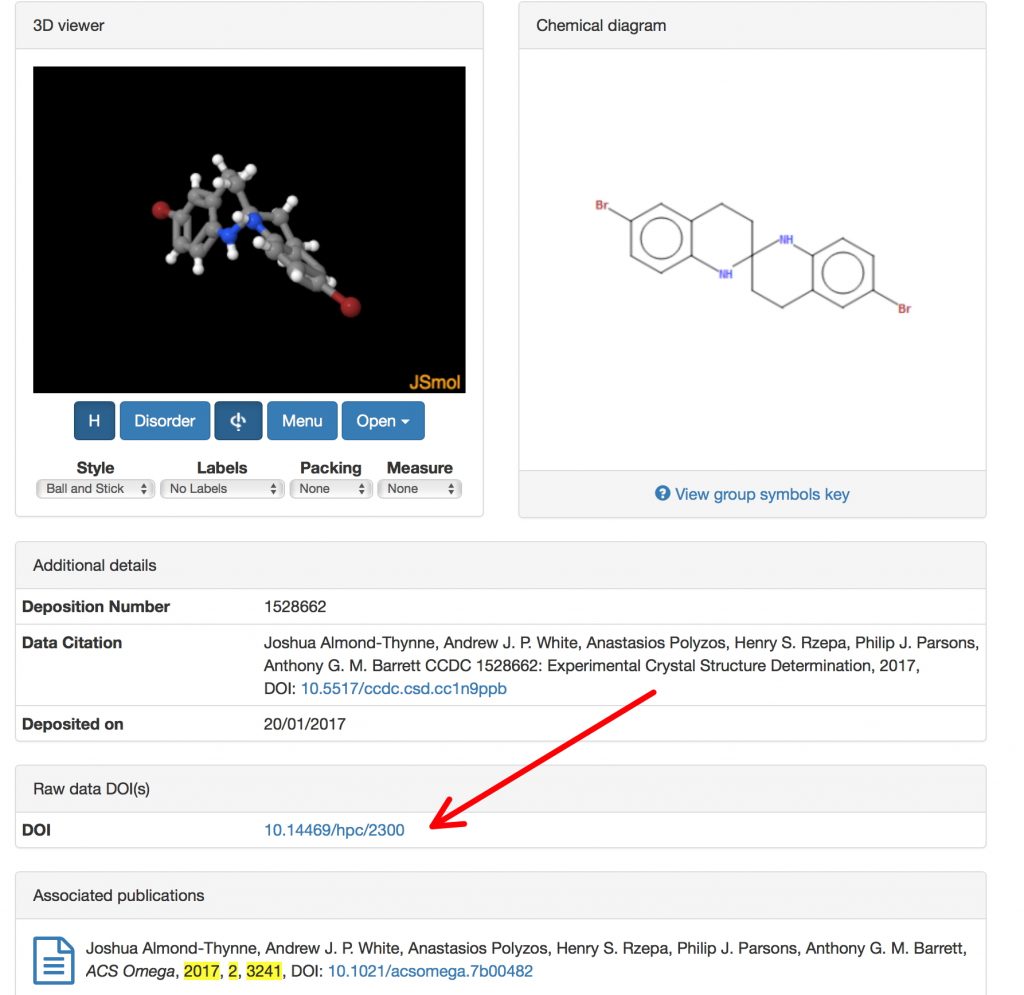
C&EN has again run a vote for the 2017 Molecules of the year. Here I take a look not just at these molecules, but at how FAIR (Findable, Accessible, Interoperable and Reusable) the data associated with these molecules actually is. I went about finding out as follows: The article DOI for all seven candidates was linked to the C&EN site.
The topic of open citations was presented at the PIDapalooza conference and represents a third component in the increasing corpus of open scientific information. David Shotton gave us an update on Citations as First Class data objects – Citation Identifiers and introduced (me) to the blog where he discusses this topic.

Another occasional conference report (day 1). So why is one about “persistent identifiers” important, and particularly to the chemistry domain? The PID most familiar to most chemists is the DOI (digital object identifier). In fact there are many; some 60 types have been collected by ORCID (themselves purveyors of researcher identifiers). They sometimes even have different names;
FAIR data is increasingly accepted as a description of what research data should aspire to; **F**indable, **A**ccessible, **I**nter-operable and R e-usable, with Context added by rich metadata (and also that it should be Open). But there are two sides to data, one of which is the raw data emerging from say an instrument or software simulations and the other in which some kind of model is applied to produce semi-
PIDapalooza is a new forum concerned with discussing all things persistent, hence PID. You might wonder what possible interest a chemist might have in such an apparently arcane subject, but think of it in terms of how to find the proverbial needle in a haystack in a time when needles might look all very similar.
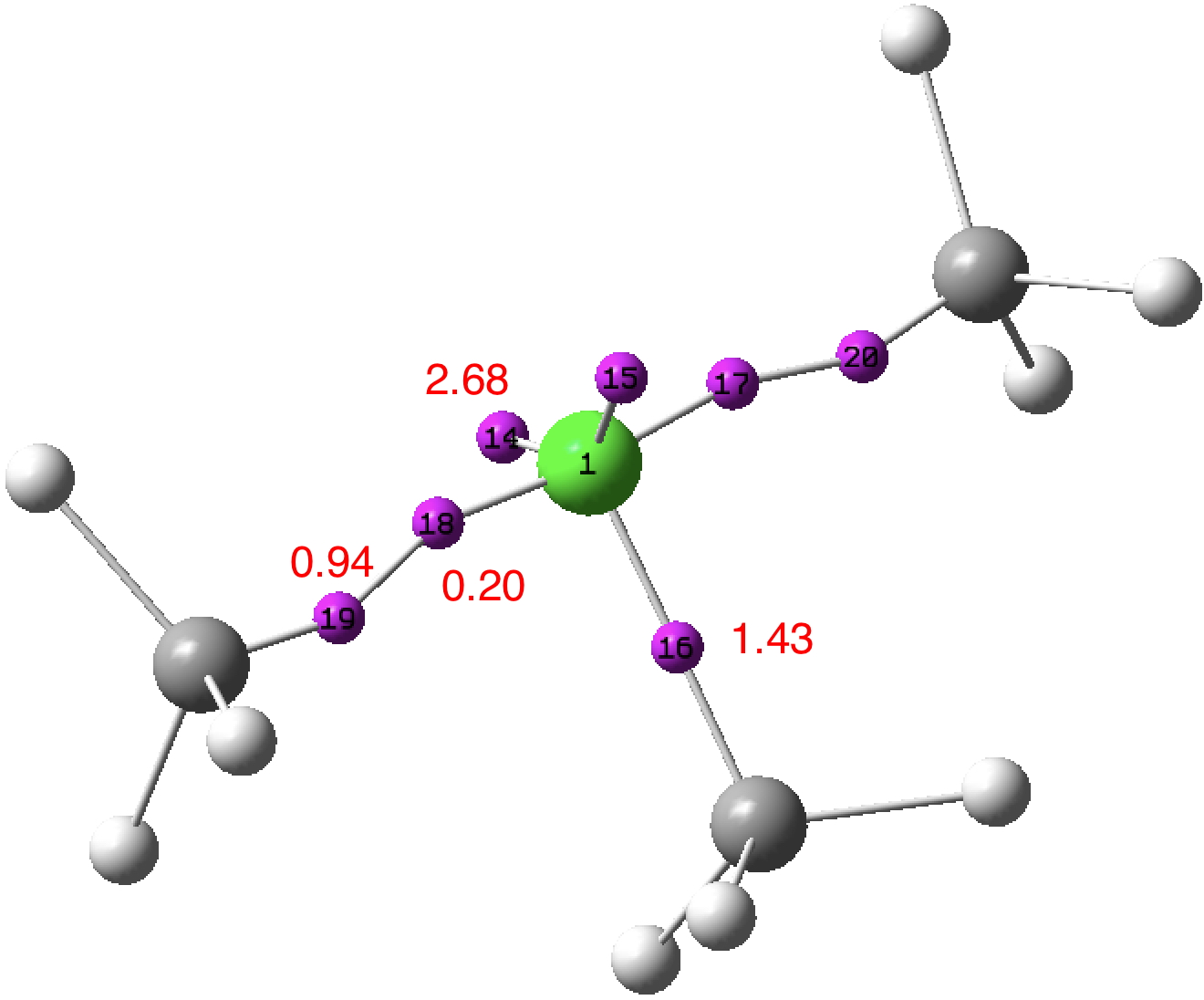
A few years back, I took a look at the valence-shell electron pair repulsion approach to the geometry of chlorine trifluoride, ClF 3 using so-called ELF basins to locate centroids for both the covalent F-Cl bond electrons and the chlorine lone-pair electrons.
We have heard a lot about OA or Open Access (of journal articles) in the last five years, often in association with the APC (Article Processing Charge) model of funding such OA availability. Rather less discussed is how the model of the peer review of these articles might also evolve into an Open environment. Here I muse about two experiences I had recently.