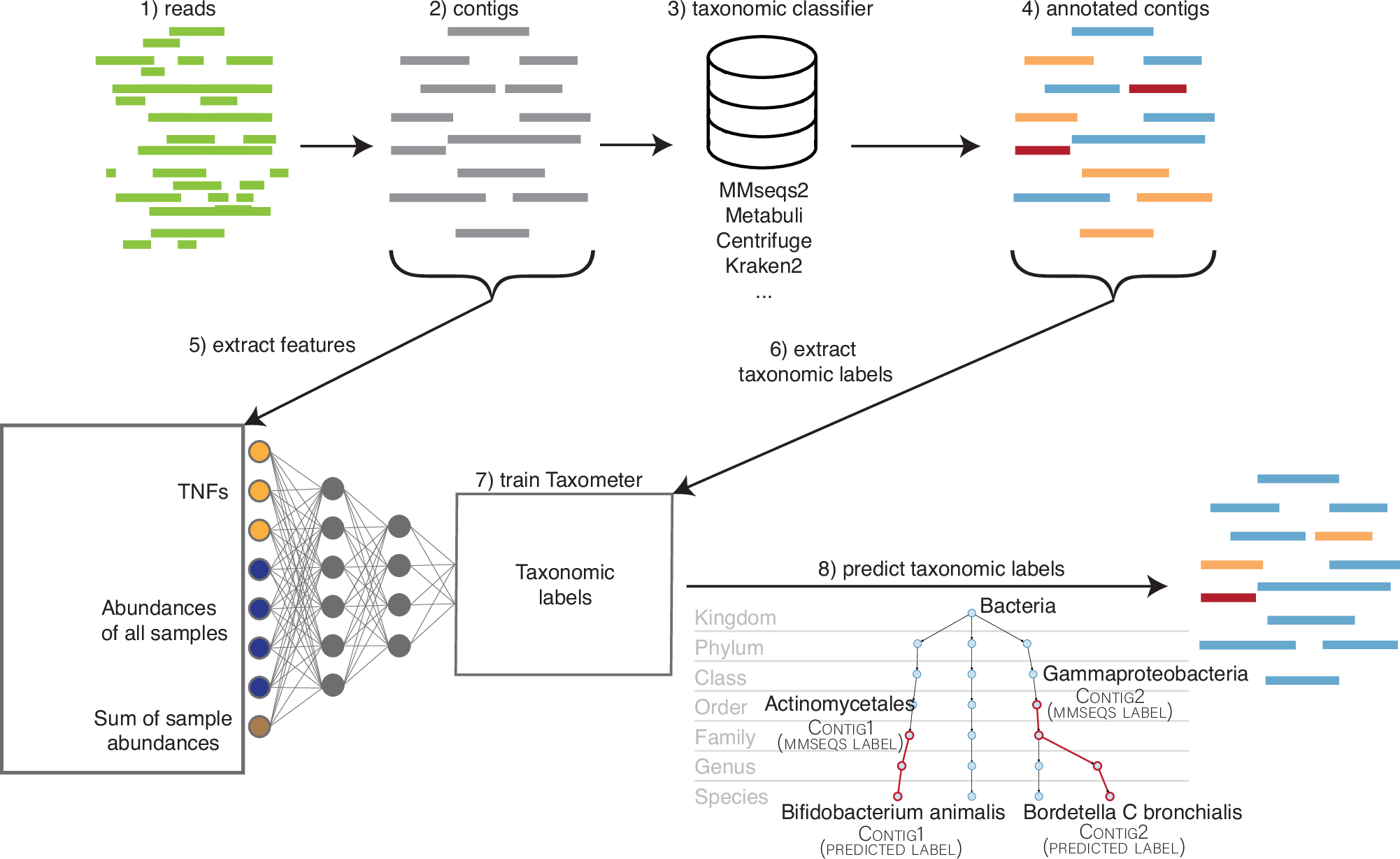
Published
Author Stephen Turner

I just returned from a week in Barcelona where I attended the Nextflow Summit and nf-core hackathon, and I can hardly contain my excitement for the near term future of bioinformatics, computational biology, and open science in general.