PapersBiological Sciences
Published
Author Stephen Turner
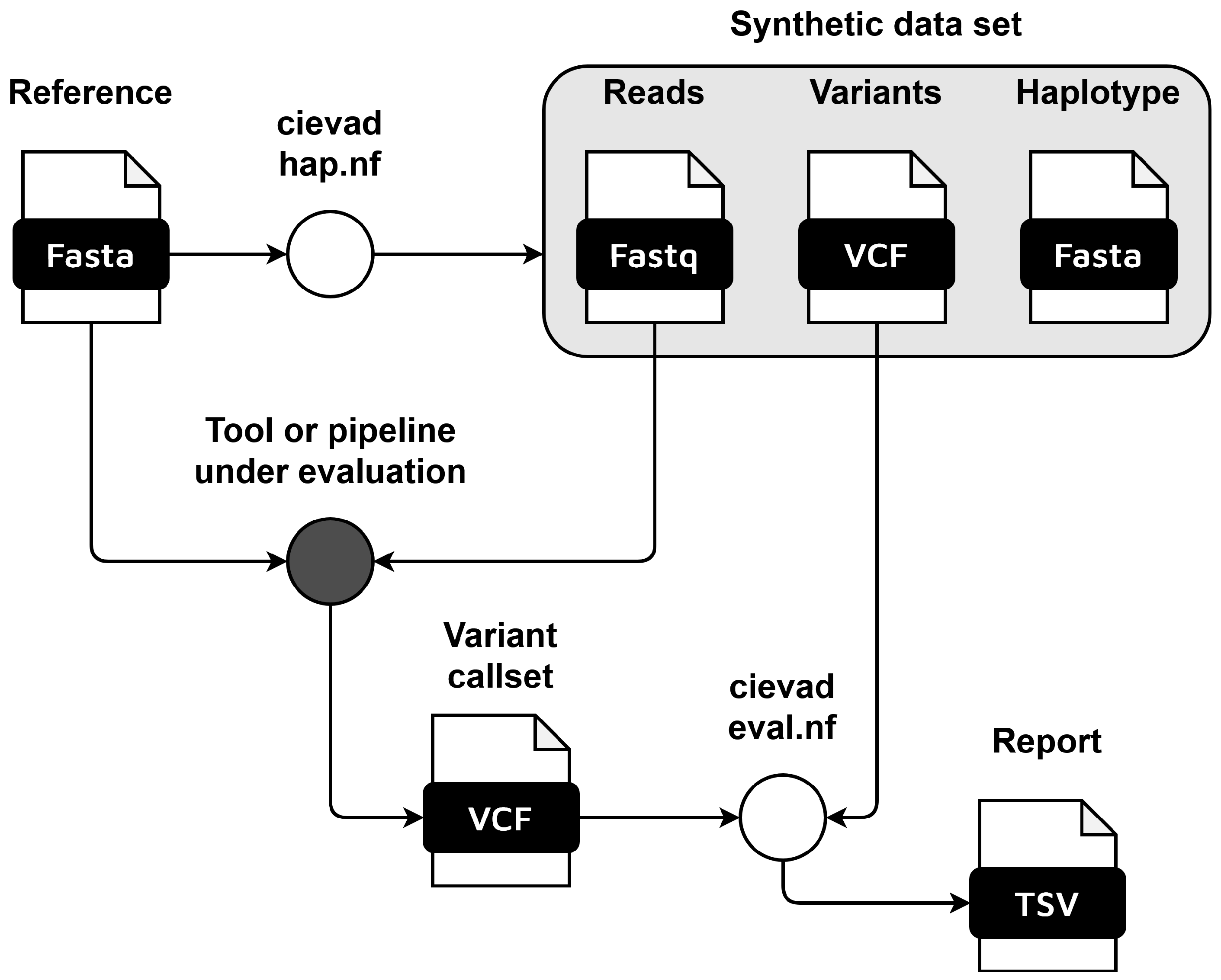
This week's recap highlights a new pipeline for metagenome quality assessment and taxonomic annotation (MAGFlow &
This week's recap highlights a new pipeline for metagenome quality assessment and taxonomic annotation (MAGFlow &

I just returned from a week in Barcelona where I attended the Nextflow Summit and nf-core hackathon, and I can hardly contain my excitement for the near term future of bioinformatics, computational biology, and open science in general.
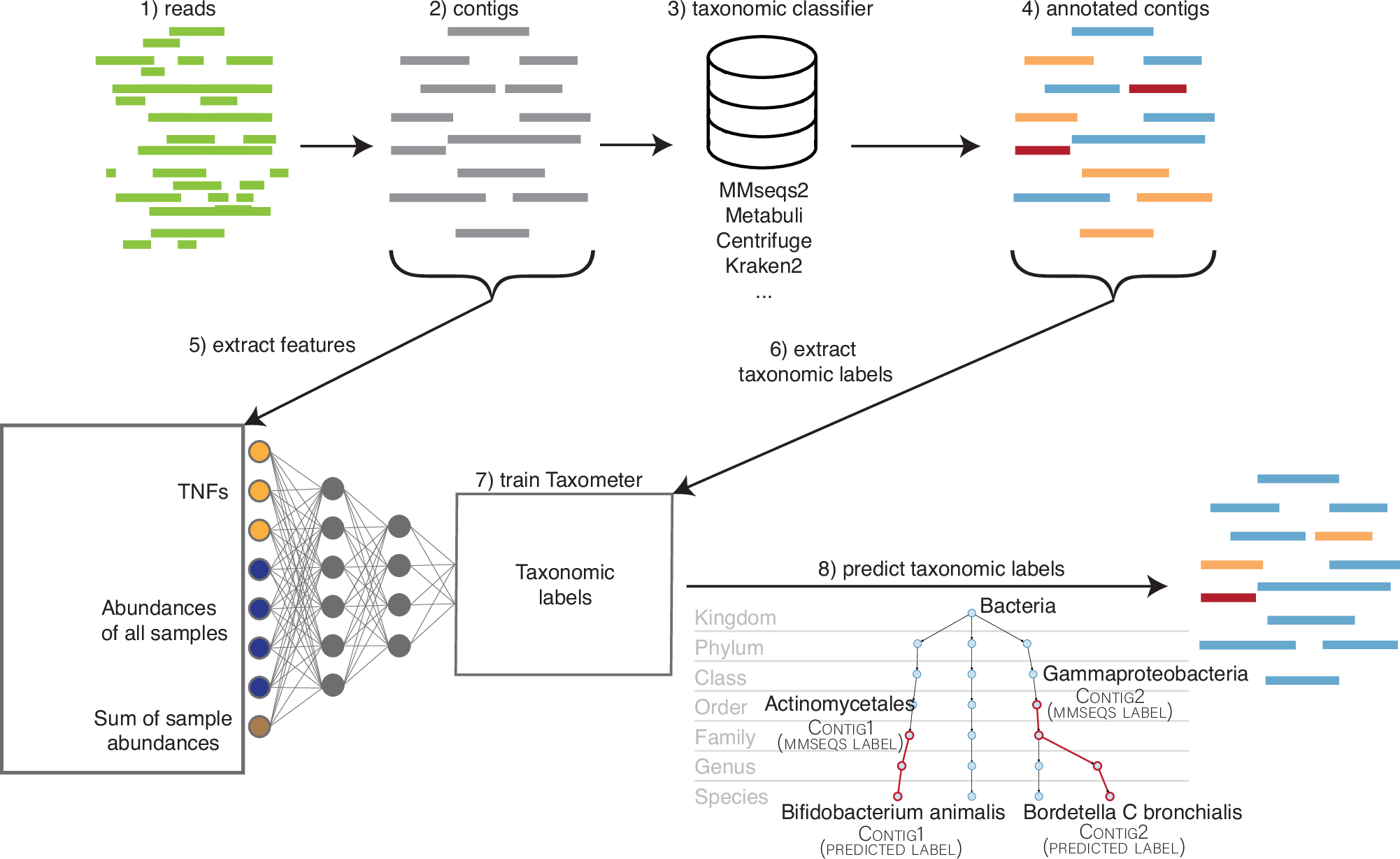
This week’s recap highlights protein design with RoseTTAFold, surveillance with wastewater sequencing, T2T human genomes, Vitessce for visualization of multimodal spatial single-cell data, and Taxometer for taxonomic classification of metagenomics contigs.

A Google search for “R vs Python” returns thousands of hits across sites like Reddit, IBM, Datacamp, Coursera, Kaggle, and many others. A quick Google Trends analysis shows that this search query has grown steadily over the last decade. Any real data scientist would agree that this argument is silly, that the right answer is to use the best tool for the job. What’s “best” isn’t always easy to answer.

This week’s recap highlights a new Nextflow workflow for calculating polygenic scores with adjustments for genetic ancestry, a paper demonstrating that whole exome plus imputation on more samples is more powerful than whole genome sequencing for finding more trait associated variants, a new deep-learning-based splice site predictor that improves spliced alignments, a new method for accurate community profiling of large metagenomic datasets, and

I am in the middle of writing a review / perspectives paper. One that I’m confident will be exciting once we get it published. Some sections of the review cover subject matter at the outer periphery of my expertise.
This week’s recap highlights a new method for gene-level alignment of single-cell trajectories, an R package for integrating gene and protein identifiers across biological sequence databases, characterization of SVs across humans and apes, universal prediction of cellular phenotypes, a method to quantify cell state heritability versus plasticity and infer cell state transition with single cell data, and a new AI-driven, natural language-oriented

Yesterday I wrote about base R vs. dplyr vs. duckdb for a simple summary analysis. In that post I simulated 100 million rows of a dataset and wrote to disk as CSV. I then benchmarked how long it took to read in and compute a simple grouped mean. One thing I didn’t do here was separate the time it took to read data into memory (for base R and dplyr) versus computing the actual summary.

TL;DR : For a very simple analysis (means by group on 100M rows), duckdb was 125x faster than base R, and 28x faster than readr+dplyr, without having to read data from disk into memory. The duckplyr package wraps DuckDB's analytical query processing techniques in a dplyr-compatible API. Learn more at duckdb.org/docs/api/r and duckplyr.tidyverse.org. I wanted to see for myself what the fuss was about with DuckDB.

This week’s recap highlights a new multispecies codon optimization method, personalized pangenome references with vg, a commentary on the wild west of spike-in normalization, a new pipeline for comprehensive and scalable polygenic scoring across ancestrally diverse populations, a paper showing deep learning / transformer-based methods don’t outperform simple linear models for predicting gene expression after genetic perturbations, and finally, a

TL;DR: Codeium offers a free Copilot-like experience in Positron. You can install it from the Open VSX registry directly within the extensions pane in Positron.