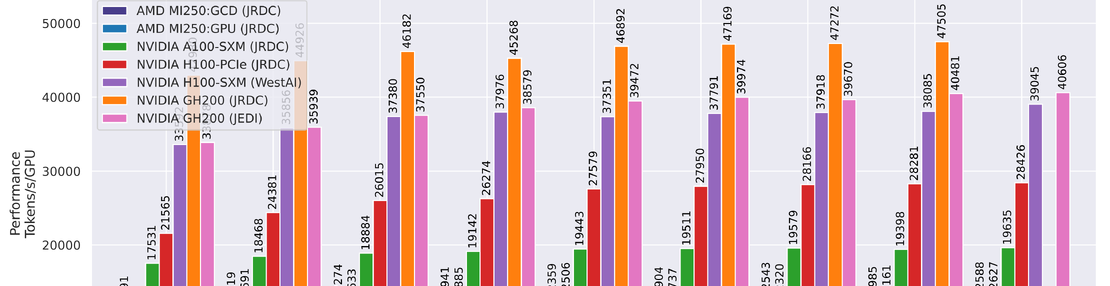
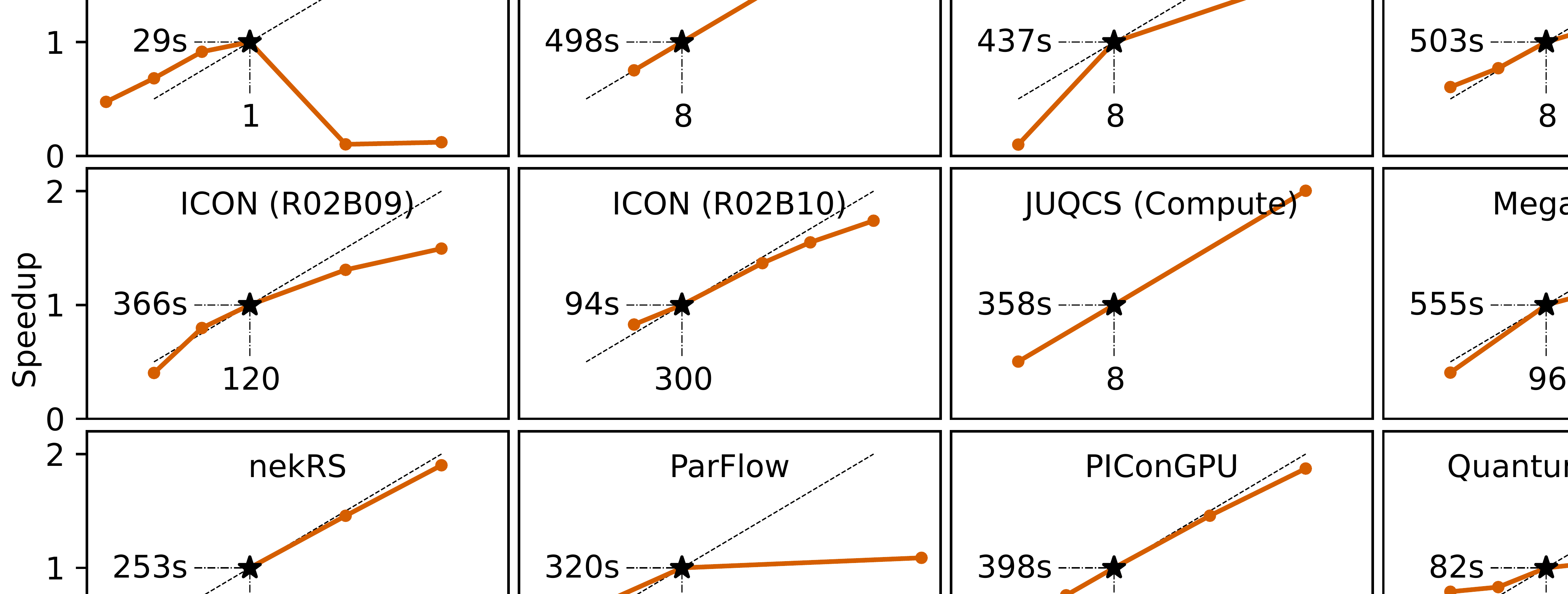
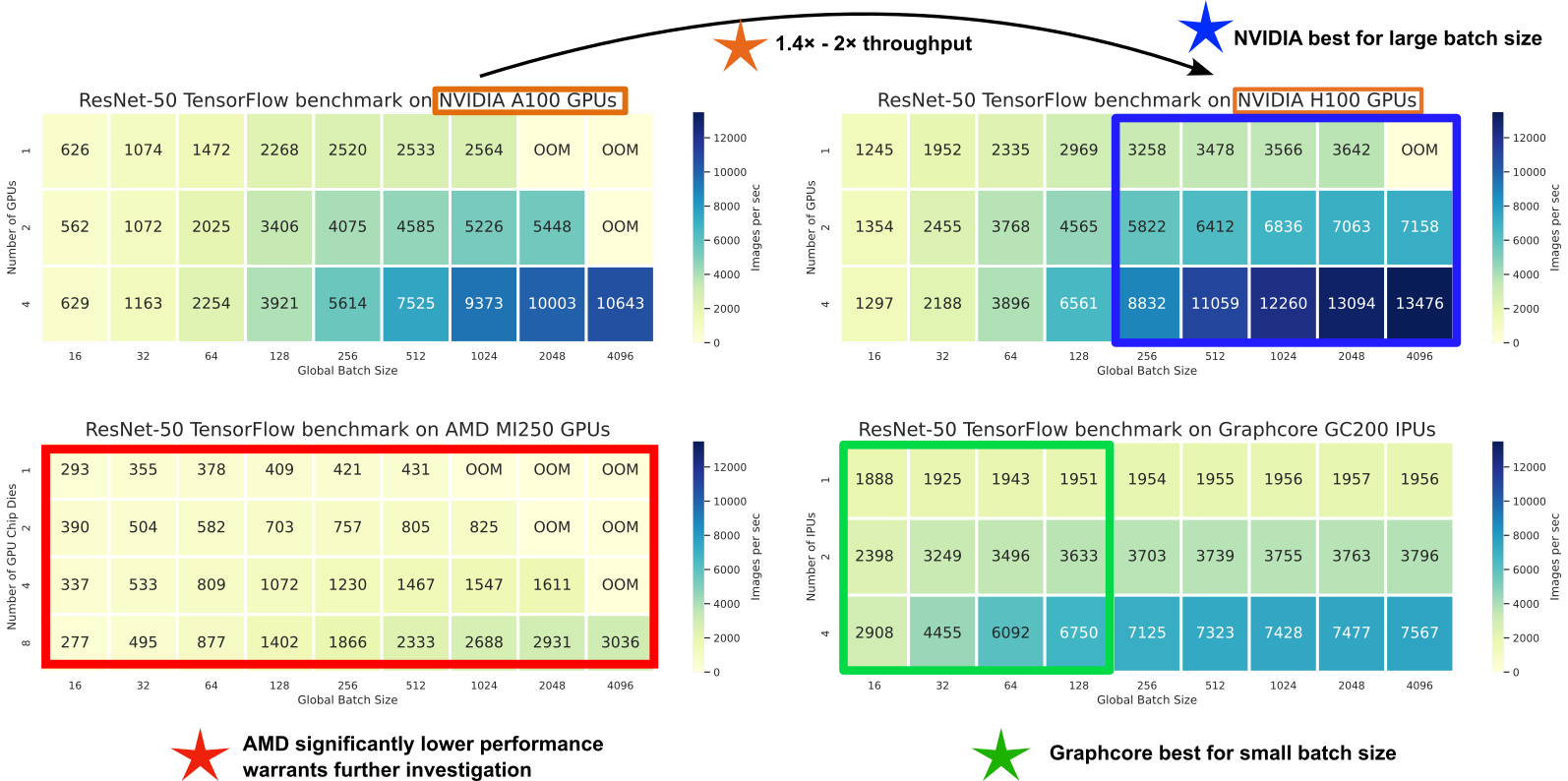
HPCGPUPosterGraphsSCcategories.electricalEngineeringElectronicEngineeringInformationEngineering
Published
Author Adel Dabah
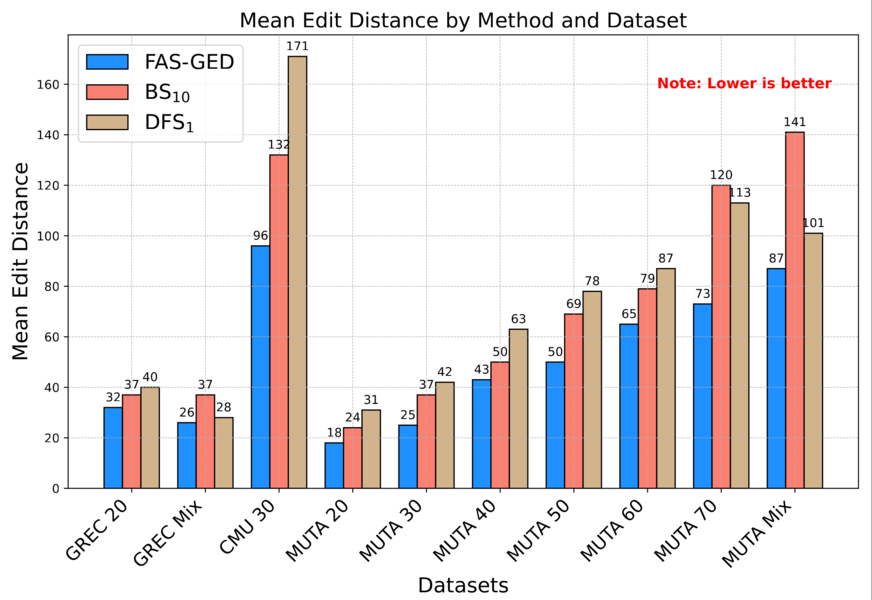
** Poster in institute repository:** https://doi.org/10.34734/FZJ-2024-06811 Graphs are powerful tools for representing real-world objects and relations in numerous domains, such as bioinformatics, pattern recognition, and computer vision. However, quantifying their similarity or difference is crucial despite the computationally expensive execution.