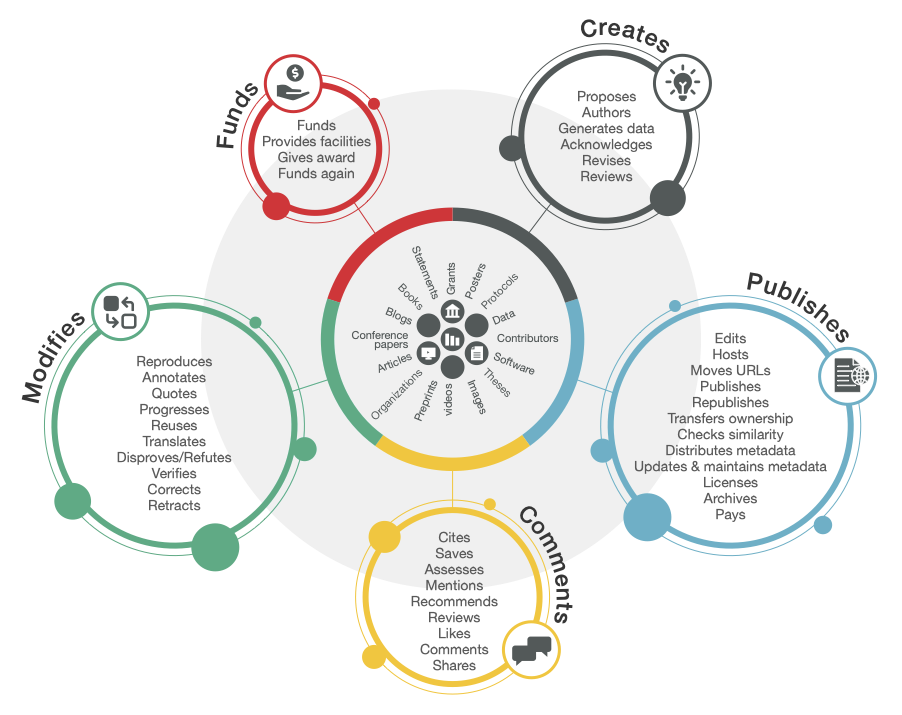
CommunityCrossrefGrant Linking SystemIdentifiersMetadataInformatikEnglisch
Veröffentlicht
Autoren Rocío Gaudioso Pedraza, Katharina Rieck
Click here for the version in German As a new Community Engagement Manager at Crossref, dedicated to working with the funders community, I frequently hear requests for examples and case studies of adopting Crossref’s Grant Linking System (GLS) by ‘funders like us’. This has spurred me to start a series of