Published in Front Matter
Author Martin Fenner
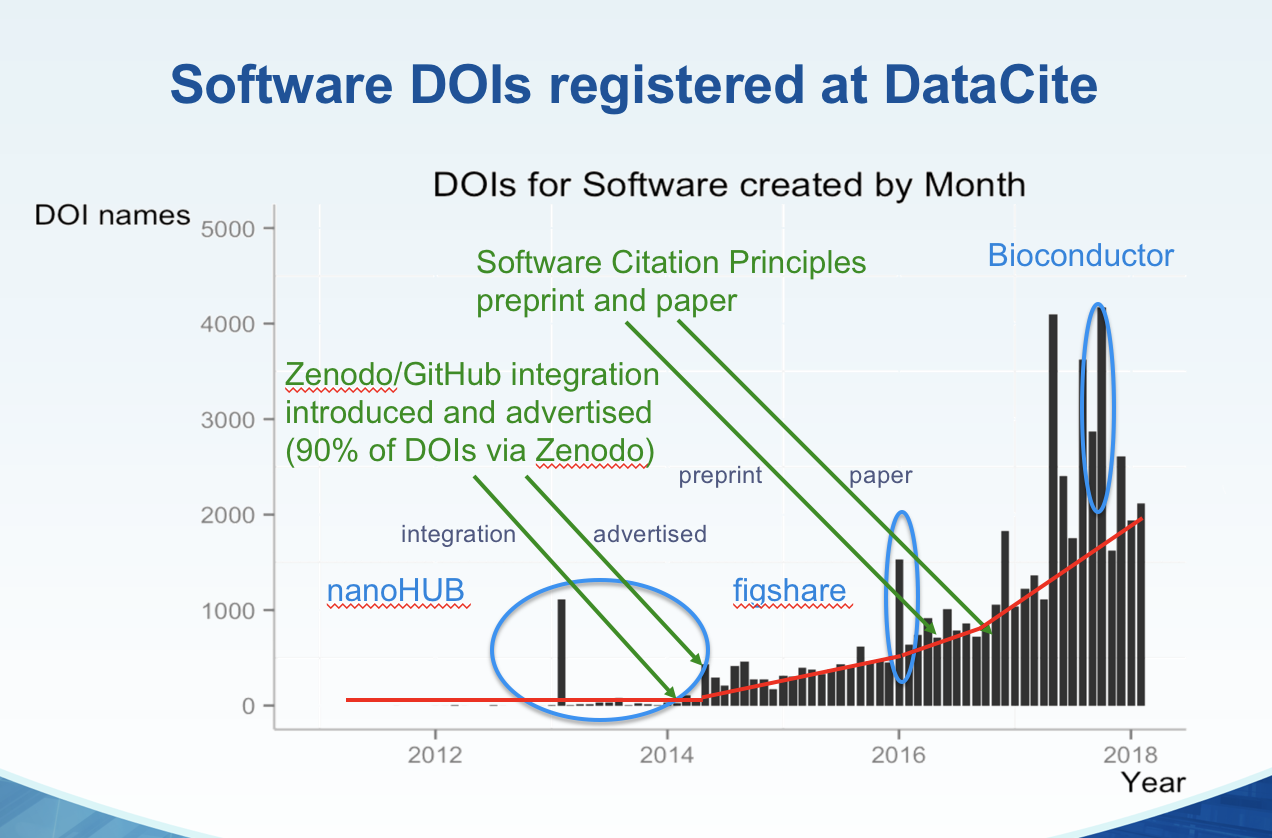
We know that software is important in research, and some of us in the scholarly communications community, for example, in FORCE11, have been pushing the concept of software citation as a method to allow software developers and maintainers to get academic credit for their work: software releases are published and assigned DOIs, and software users then cite these releases when they publish research that uses the software.