Jerven Bolleman
et al.
recently published a great preprint about how to use RDF to give SPARQL queries context by linking it (semantically) with metadata. The context includes keywords, the SPARQL endpoint the query can be run against, and a human-oriented description of the query.
Authors Jerven Bolleman, Vincent Emonet, Adrian Altenhoff, Amos Bairoch, Marie-Claude Blatter, Alan Bridge, Severine Duvaud, Elisabeth Gasteiger, Dmitry Kuznetsov, Sebastien Moretti, Pierre-Andre Michel, Anne Morgat, Marco Pagni, Nicole Redaschi, Monique Zahn-Zabal, Tarcisio Mendes de Farias, Ana Claudia Sima
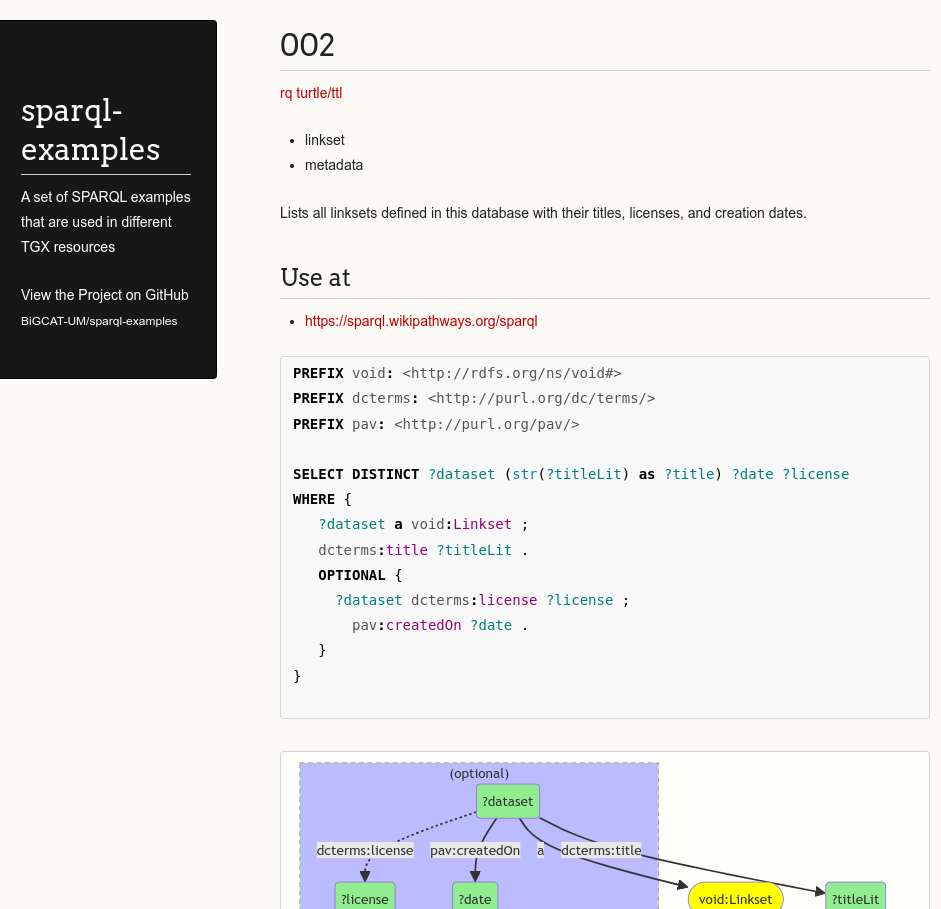
Background. In the last decades, several life science resources have structured data using the same framework and made these accessible using the same query language to facilitate interoperability. Knowledge graphs have seen increased adoption in bioinformatics due to their advantages for representing data in a generic graph format. For example, yummydata.org catalogs more than 60 knowledge graphs accessible through SPARQL, a technical query language. Although SPARQL allows powerful, expressive queries, even across physically distributed knowledge graphs, formulating such queries is a challenge for most users. Therefore, to guide users in retrieving the relevant data, many of these resources provide representative examples. These examples can also be an important source of information for machine learning, if a sufficiently large number of examples are provided and published in a common, machine-readable and standardized format across different resources.
Findings. We introduce a large collection of human-written natural language questions and their corresponding SPARQL queries over federated bioinformatics knowledge graphs (KGs) collected for several years across different research groups at the SIB Swiss Institute of Bioinformatics. The collection comprises more than 1000 example questions and queries, including 65 federated queries. We propose a methodology to uniformly represent the examples with minimal metadata, based on existing standards. Furthermore, we introduce an extensive set of open-source applications, including query graph visualizations and smart query editors, easily reusable by KG maintainers who adopt the proposed methodology.
Conclusions. We encourage the community to adopt and extend the proposed methodology, towards richer KG metadata and improved Semantic Web services.