Published in rOpenSci - open tools for open science
Author Jeroen Ooms
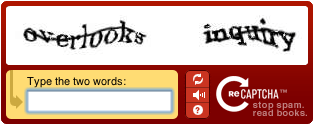
Optical character recognition (OCR) is the process of extracting written or typed text from images such as photos and scanned documents into machine-encoded text. The new rOpenSci package tesseract brings one of the best open-source OCR engines to R. This enables researchers or journalists, for example, to search and analyze vast numbers of documents that are only available in printed form.